Kafka S3 Sink Connector의 시간 기반 파일 로테이션
들어가며: S3 파일은 언제 업로드될까?
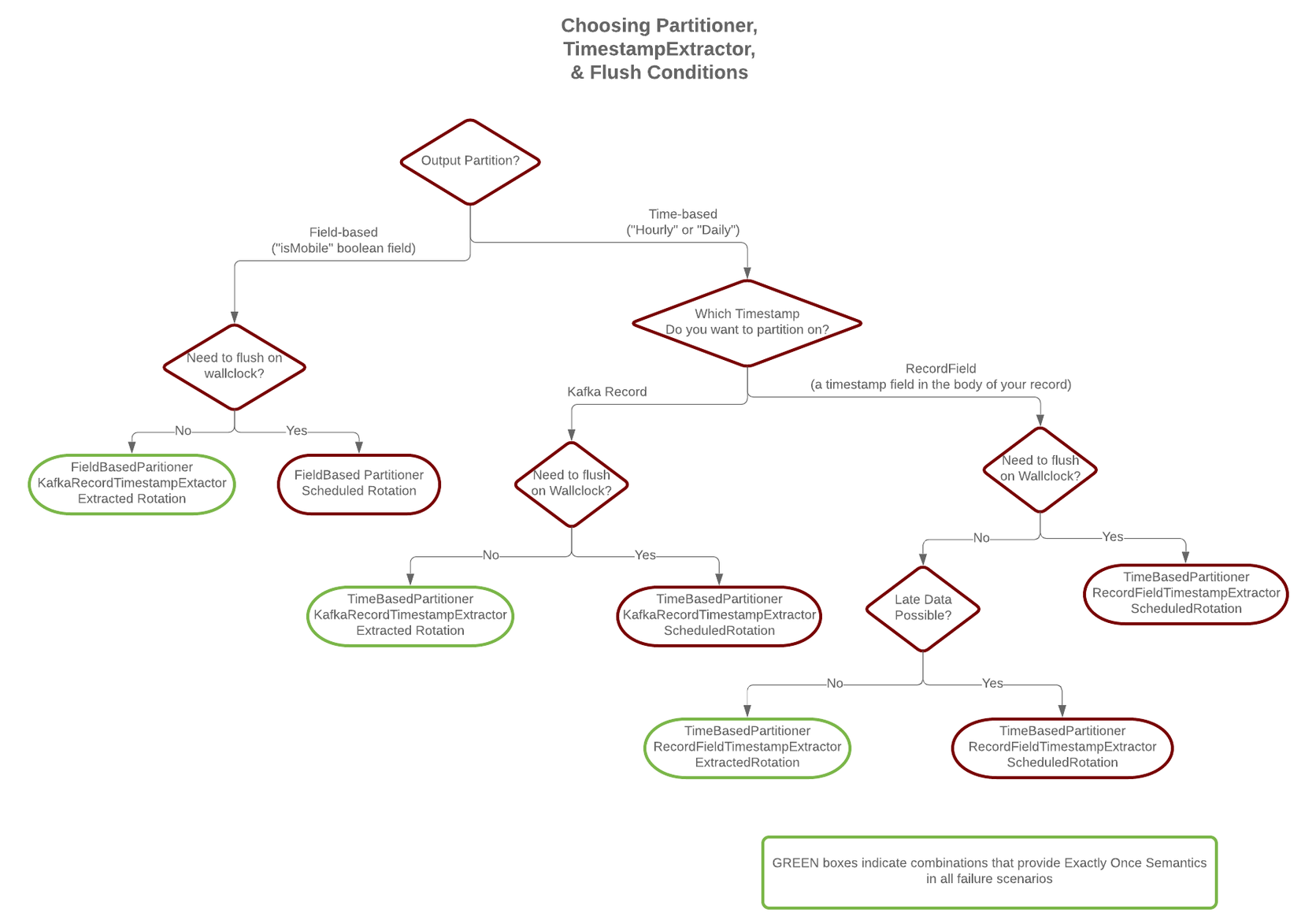
Apache Kafka® S3 Sink Connector는 Kafka 토픽의 데이터를 S3 버킷으로 적재할 때 많이 쓰는 도구입니다. 커넥터는 레코드를 버퍼링하다가 특정 조건이 충족되면 하나의 파일(오브젝트)로 묶어 S3에 업로드합니다. 이 과정을 파일 로테이션(File Rotation) 이라고 합니다.
파일 로테이션을 결정하는 조건에는 레코드 개수(flush.size), 파일 크기(file.size) 등 여러 가지가 있지만, 가장 흔하게 사용되면서도 혼동하기 쉬운 것이 바로 시간 기반 로테이션 입니다. S3 Sink Connector는 시간 기반 로테이션을 위해 rotate.interval.ms와 rotate.schedule.interval.ms라는 두 가지 주요 속성을 제공합니다.
두 속성은 이름이 비슷하지만 동작 기준과 보장 수준이 다릅니다. 잘못 선택하면 데이터 적재 지연이나 중복으로 이어질 수 있습니다. 이 글에서는 두 속성의 차이를 정리합니다.
핵심 차이점 비교
먼저 두 속성의 차이를 표로 정리합니다.
| 구분 | rotate.interval.ms | rotate.schedule.interval.ms |
|---|---|---|
| 로테이션 기준 | 레코드의 타임스탬프 | 커넥터 시스템의 시간 (Wall-Clock Time) |
| 데이터 연속성 | 지속적인 데이터 스트림이 필요함 | 지속적인 데이터 스트림이 필요 없음 |
| 주요 사용 사례 | 이벤트 시간(Event Time) 기반 파티셔닝 | 수집 시간(Ingestion Time) 기반 파티셔닝 |
| Exactly-Once 보장 | 가능 (다른 조건 충족 시) | 불가능 |
1. rotate.interval.ms: 레코드 타임스탬프 기준 로테이션
이 속성은 레코드에 포함된 타임스탬프 를 기준으로 로테이션을 결정합니다. 동작 방식은 다음과 같습니다.
- 커넥터가 새 파일에 첫 번째 레코드를 쓸 때, 해당 레코드의 타임스탬프를 기록하여 시간 창(Time Window)을 시작합니다.
- 이후 들어오는 레코드들의 타임스탬프를 계속 확인합니다.
- 새로 들어온 레코드의 타임스탬프가
(첫 레코드의 타임스탬프 + rotate.interval.ms)를 초과 하면, 커넥터는 기존 파일을 닫고 S3에 업로드한 후, 새 레코드로 새 파일을 시작합니다.
rotate.interval.ms의 장점과 단점
- 장점: 레코드의 이벤트 발생 시간을 기준으로 파일을 나눌 수 있어, 시간대별 데이터 분석에 유용합니다. 또한 로테이션 결정이 데이터 자체에 의해 이루어지므로 결정론적(deterministic) 이며, 이는 Exactly-Once Semantics(EOS)를 구현하는 조건 중 하나가 됩니다.
- 단점: 이 방식은 새로운 레코드가 들어와야만 로테이션 여부를 판단할 수 있습니다. Kafka 토픽으로 데이터 유입이 드물거나 중단되면, 마지막 파일이 닫히지 않고 커넥터에 계속 열린 상태로 남습니다. 이 경우 S3 적재가 지연될 수 있습니다.
예시 (rotate.interval.ms = 3000ms):
| 레코드 타임스탬프 | 오프셋 | 동작 |
|---|---|---|
| 1706713200000 | 100 | 새 파일 시작. 이 파일의 시간 창은 1706713200000 ~ 1706713202999 |
| 1706713201000 | 101 | 현재 파일에 데이터 추가 |
| 1706713202000 | 102 | 현재 파일에 데이터 추가 |
| 1706713204000 | 103 | 시간 창을 초과! 기존 파일(offset 100-102)을 닫고 업로드. 새 파일 시작. |
만약 오프셋 103번 레코드가 들어오지 않으면, 오프셋 100-102번을 담고 있는 파일은 계속 열려있게 됩니다.
2. rotate.schedule.interval.ms: 시스템 시간 기준 로테이션
이 속성은 레코드의 내용과 무관하게, 커넥터가 실행 중인 서버의 시스템 시간(Wall-Clock Time) 을 기준으로 로테이션을 결정합니다. 즉, “주기적으로 창고를 정리하는 스케줄러"와 같습니다.
- 동작 방식: 설정된 시간 간격마다 커넥터가 현재 버퍼링하고 있는 데이터를 파일로 닫아 S3에 업로드합니다. 예를 들어
300000(5분)으로 설정하면, 데이터 유입 여부와 상관없이 5분마다 주기적으로 파일을 업로드합니다. - 이 속성을 사용하려면 반드시
timezone속성을 함께 설정해야 합니다.
rotate.schedule.interval.ms의 장점과 단점
- 장점: 데이터 스트림이 간헐적이거나 중단되더라도, 주기적으로 데이터가 S3에 업로드되는 것을 보장 합니다. 데이터 적재 지연을 줄이는 데 도움이 됩니다.
- 단점: 로테이션 시점이 커넥터의 실행 시간에 따라 달라지므로 비결정론적(non-deterministic) 입니다. 만약 커넥터가 재시작되면 스케줄이 초기화되어, 재시작 전후에 동일한 레코드셋에 대해 파일이 다르게 나뉠 수 있습니다. 이 때문에 Exactly-Once Semantics(EOS)를 보장할 수 없으며, 데이터 중복이 발생할 수 있습니다.
Exactly-Once Semantics (EOS)와 로테이션 전략
S3 Sink Connector에서 EOS를 보장하려면, 어떤 상황에서든(특히 커넥터 재시작 시) 동일한 Kafka 레코드들이 항상 동일한 S3 객체에 쓰여야 합니다. 즉, 파티셔닝과 파일 로테이션이 결정론적 이어야 합니다.
rotate.interval.ms는 레코드의 타임스탬프라는 데이터 고유의 값에 기반하므로 결정론적입니다. 커넥터가 재시작되어 동일한 레코드를 다시 처리하더라도, 파일이 나뉘는 기준(타임스탬프)이 동일하므로 항상 같은 이름의 S3 객체를 생성하여 덮어쓰게 됩니다. 이것이 EOS를 가능하게 합니다.rotate.schedule.interval.ms는 커넥터의 실행 시간이라는 외부 요인에 기반하므로 비결정론적입니다. 재시작 시점에 따라 파일이 나뉘는 경계가 달라져 중복된 데이터를 가진 다른 이름의 파일이 생성될 수 있습니다.
Confluent 공식 문서에서도 EOS를 위해서는 rotate.interval.ms 사용이 필수 조건 중 하나임을 명시하고 있습니다.
결론 및 권장 사항
두 로테이션 전략은 데이터 파이프라인 요구사항에 따라 선택합니다.
rotate.interval.ms를 선택해야 하는 경우:- Exactly-Once Semantics(EOS)가 반드시 필요한 경우
- 이벤트 발생 시간을 기준으로 데이터를 분석해야 하는 경우
- 데이터가 거의 끊임없이 지속적으로 유입되는 환경
rotate.schedule.interval.ms를 선택해야 하는 경우:- 데이터 유입이 드물거나 간헐적인 경우
- EOS가 필수는 아니며, 최소 한 번 이상 처리(At-Least-Once)로 충분한 경우
- 데이터 적재 지연을 방지 하는 것이 가장 중요한 목표인 경우
운영 환경에서는 rotate.interval.ms를 기본 전략으로 쓰고, rotate.schedule.interval.ms를 안전장치(fallback)처럼 함께 설정하기도 합니다. 이렇게 하면 데이터 유입이 끊겨도 일정 시간이 지나면 파일이 업로드됩니다. 다만 이 경우 EOS는 보장되지 않습니다.
참고 자료:
이 글은 AI의 도움을 받아 교정 및 정리되었습니다.