응집도(Cohesion)와 LCOM으로 설계 품질 살펴보기
응집도란 무엇인가?
소프트웨어 공학에서 응집도(Cohesion) 는 하나의 모듈(클래스, 컴포넌트 등) 안에 있는 구성 요소들이 얼마나 밀접하게 관련되어 있는지를 나타내는 척도입니다. 응집도가 높은 모듈 은 보통 명확한 하나의 책임(Single Responsibility)을 가지며, 코드를 이해하고 테스트하고 고치기 쉽습니다. 반대로 응집도가 낮은 모듈은 관련 없는 기능이 섞여 있어 변경할 때 예상치 못한 영향을 만들기 쉽습니다.
좋은 소프트웨어 설계는 대체로 높은 응집도(High Cohesion) 와 낮은 결합도(Low Coupling) 를 지향합니다. 이 글에서는 응집도의 유형을 정리하고, LCOM이라는 메트릭으로 클래스 응집도를 어떻게 살펴볼 수 있는지 다룹니다.
응집도의 7가지 유형
응집도는 그 수준에 따라 7가지 유형으로 나눌 수 있습니다. 가장 바람직한 기능적 응집 부터 가장 피해야 할 우연적 응집 까지 순서대로 보겠습니다.
1. 기능적 응집 (Functional Cohesion) - 가장 이상적인 형태
모듈 내의 모든 기능이 단 하나의 목적 을 달성하기 위해 함께 동작하는 경우입니다. 가장 바람직한 형태의 응집도입니다.
- 예시:
calculateRectangleArea(width, height)함수는 사각형의 넓이를 계산하는 단일 목적에만 집중합니다. 이 함수에 필요한 모든 로직(입력 유효성 검사, 곱셈 연산 등)은 오직 ‘넓이 계산’이라는 목표를 위해 존재합니다.
2. 순차적 응집 (Sequential Cohesion)
한 요소의 출력 데이터가 다음 요소의 입력 데이터로 사용되는, 마치 конвейер 벨트처럼 구성 요소들이 순차적으로 실행 되는 경우입니다.
- 예시: 파일에서 데이터를 읽어와(
readData) → 데이터를 파싱하고(parseData) → 그 결과를 데이터베이스에 저장하는(saveData) 모듈이 있다면, 각 단계는 순서대로 실행되며 이전 단계의 결과물을 사용하므로 순차적 응집을 가집니다.
3. 소통적/교환적 응집 (Communicational Cohesion)
동일한 입력 데이터(자료구조)를 사용하거나 동일한 출력 데이터를 생성하는 등, 동일한 데이터를 공유 하는 구성 요소들이 모여있는 경우입니다.
- 예시:
Book객체를 받아, 그 책의 제목, 저자, 가격 정보를 모두 업데이트하는updateBookDetails메서드가 있다면, 이 메서드 내부의 작업들은 모두 동일한Book데이터를 공유하므로 소통적 응집을 가집니다.
4. 절차적 응집 (Procedural Cohesion)
구성 요소들이 반드시 동일한 데이터를 공유하지는 않지만, 특정 실행 순서 에 따라 함께 그룹화되는 경우입니다. 순차적 응집과 비슷하지만, 데이터 흐름보다는 제어 흐름(순서)에 더 중점을 둡니다.
- 예시: 사용자가 로그인할 때,
checkPermissions()를 호출하여 권한을 확인하고, 성공하면openDatabaseConnection()을 호출하고, 마지막으로logUserAccess()를 호출하는 일련의 과정은 정해진 절차에 따라 실행되므로 절차적 응집의 예입니다.
5. 시간적 응집 (Temporal Cohesion)
구성 요소들이 기능적으로는 관련이 없지만, 특정 시점 에 함께 실행되어야 하는 작업들이 모여있는 경우입니다.
- 예시: 애플리케이션 시작 시 실행되는
initializeApp()메서드 안에 설정 파일 로드, 데이터베이스 연결 초기화, 캐시 비우기 등 서로 다른 작업들이 모여 있다면, 이는 시간적 응집에 해당합니다. 이 작업들은 ‘시작 시’라는 시간적 제약 때문에 함께 묶여 있습니다.
6. 논리적 응집 (Logical Cohesion)
유사한 성격의 작업들이 하나의 모듈에 모여 있지만, 실제로 호출될 때는 그중 하나의 작업만 선택되어 실행 되는 경우입니다.
- 예시: 모든 종류의 에러 메시지를 출력하는
printError(errorCode)함수가 있다고 가정해 봅시다. 이 함수는errorCode에 따라 파일 에러, 네트워크 에러, 데이터베이스 에러 등 전혀 다른 종류의 메시지를 출력합니다. 이처럼 논리적으로 ‘에러 출력’이라는 범주에 속하지만, 실제로는 각기 다른 작업을 수행하는 경우 논리적 응집을 가집니다.StringUtils와 같은 유틸리티 클래스도 종종 이 유형에 속합니다.
7. 우연적/동시적 응집 (Coincidental Cohesion) - 가장 피해야 할 형태
모듈 내 구성 요소들이 아무런 의미 있는 연관 관계 없이, 단순히 우연히 같은 파일에 존재 하는 경우입니다. 이는 유지보수성과 재사용성을 심각하게 저해하는 가장 낮은 수준의 응집도입니다.
- 예시: 하나의
Utils.java파일 안에calculateFactorial()함수와sendEmail()함수,formatCurrency()함수가 함께 들어있다면, 이들은 서로 아무 관련이 없으므로 우연적 응집의 대표적인 예입니다.
LCOM: 클래스 응집도를 정량적으로 측정하기
이론적인 개념을 넘어 코드의 응집도를 객관적인 숫자로 평가하고 싶을 때 LCOM(Lack of Cohesion in Methods) 메트릭을 사용할 수 있습니다. LCOM은 클래스 내의 메서드들이 인스턴스 변수(필드)를 얼마나 공유하는지를 분석하여 응집도의 부족함(Lack of Cohesion)을 측정합니다. LCOM 점수가 높을수록 응집도가 낮다 는 의미입니다.
LCOM 활용 예: 세 가지 클래스 비교 분석
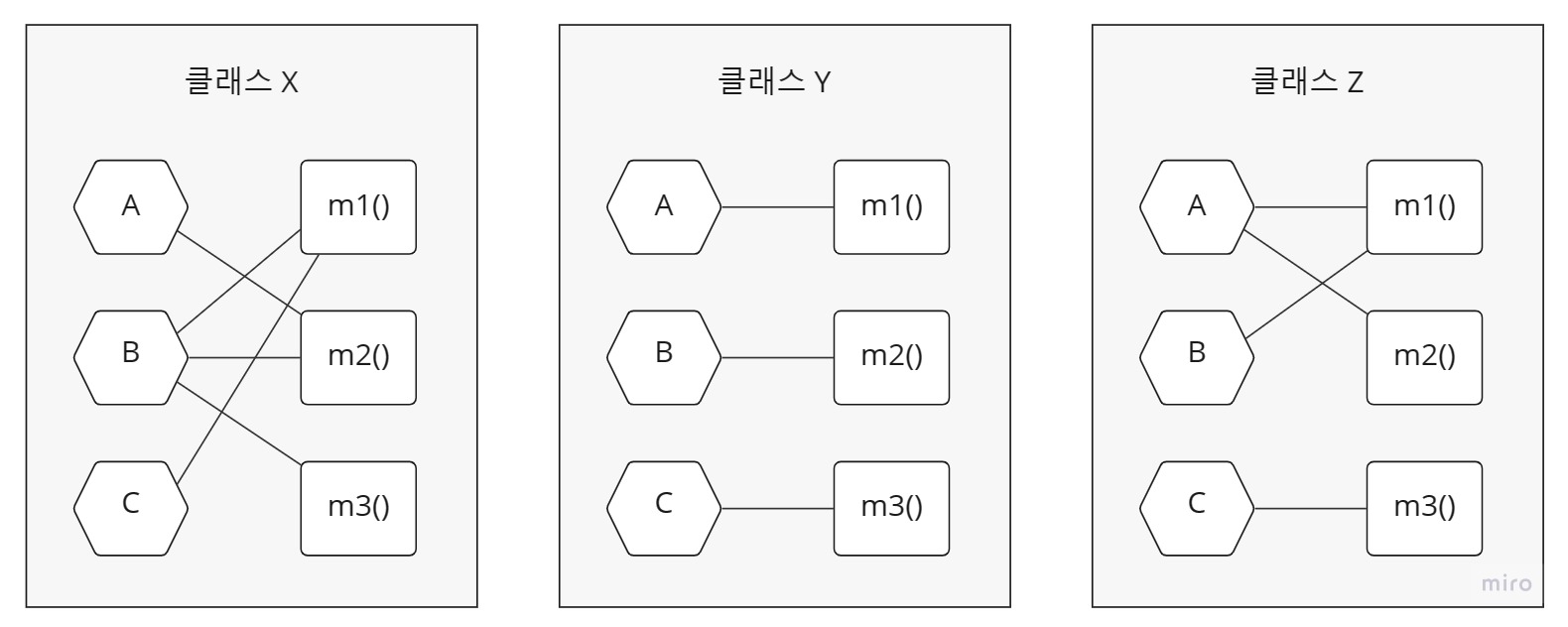
위 이미지는 LCOM을 이해하는 데 좋은 사례를 보여줍니다. 각 클래스의 응집도를 분석해 보겠습니다.
1. 클래스 X: 높은 응집도 (Good)
- 구조: 모든 메서드(m1, m2, m3)가 클래스의 모든 필드(A, B, C)를 골고루 사용하며 서로 긴밀하게 연결되어 있습니다.
- 분석: 이 클래스는 명확한 단일 책임을 가지고 있으며, 메서드와 필드들이 그 책임을 수행하기 위해 유기적으로 협력하고 있음을 보여줍니다.
- LCOM 평가: LCOM 점수가 매우 낮습니다 (즉, 응집도가 높습니다). 이는 잘 설계된 클래스의 전형적인 모습입니다.
2. 클래스 Y: 낮은 응집도 (Bad)
- 구조: 세 개의 메서드(m1, m2, m3)가 각각 자신과 관련된 필드(A, B, C)만 독립적으로 사용합니다. 메서드 간에 공유되는 필드가 전혀 없습니다.
- 분석: 이 클래스는 사실상 관련 없는 세 개의 기능이 우연히 한 클래스 안에 모여있는 것과 같습니다. 이는 우연적 또는 논리적 응집에 가깝습니다.
- LCOM 평가: LCOM 점수가 매우 높습니다 (즉, 응집도가 낮습니다). 이 경우 클래스 Y를 각각의 책임에 따라 세 개의 작은 클래스로 나누는 리팩토링을 검토할 수 있습니다.
3. 클래스 Z: 중간 수준의 응집도 (Needs Improvement)
- 구조: 두 개의 메서드(m1, m2)는 필드 A와 B를 공유하며 서로 연관되어 있지만, 메서드 m3는 필드 C만 독립적으로 사용합니다.
- 분석: 이 클래스는 두 개의 서로 다른 책임을 가지고 있을 가능성이 높습니다. 하나는 A와 B를 다루는 책임, 다른 하나는 C를 다루는 책임입니다.
- LCOM 평가: LCOM 점수가 중간 수준입니다. 응집도를 높이기 위해, m3와 필드 C를 별도의 클래스로 분리하는 것을 고려해볼 수 있습니다.
이처럼 LCOM 분석은 클래스의 설계상 결함을 발견하고, 더 나은 구조로 리팩토링하는 데 유용한 지표를 제공합니다.
결론
높은 응집도 는 좋은 설계를 판단할 때 자주 보는 기준입니다. 모듈이 하나의 명확한 책임을 갖도록 설계하면 코드를 이해하고 테스트하고 바꾸기가 쉬워집니다. 7가지 응집도 유형과 LCOM 같은 지표는 설계를 기계적으로 평가해주는 정답은 아니지만, 리팩토링이 필요한 지점을 찾는 데 좋은 출발점이 됩니다.
이 글은 AI의 도움을 받아 교정 및 정리되었습니다.